mindmap
root)Reproducibility(
3-Code
[Version]
[Github]
[Execution]
))targets((
2-Environment
🐳 [Docker]
[OS]
[Libraries]
[Environment]
[R Packages]
[Py Packages]
1-Data
[Databases]
[Blob storage]
[Archives]
The 💪 of {targets} for
Reproducible Data Science
Get ready!
Setup instructions –> https://tinyurl.com/r-targets-setup
/setup
- Have R & RStudio running
- Clone github repo:
- If you don’t have
{renv}, runinstall.packages("renv") - Run
renv::restore()to install the needed packages

/motivation/reproducibility-crisis

Not good 🙈
A survey of 1,576 researchers found that over 70% had failed to reproduce another scientist’s experiments, and more than 50% couldn’t reproduce their own results!
/motivation/reproducibility-crisis

Concerning… 😩
Scientists tried replicating 56 studies. Only 19% found results consistent with the original papers
/motivation/reproducibility-crisis

Gosh! ☠️
A 2019 paper found just 24% of 800k Jupyter notebooks on GitHub could be rerun, and only 4% reproduced the same results!
/motivation/reproducibility-crisis
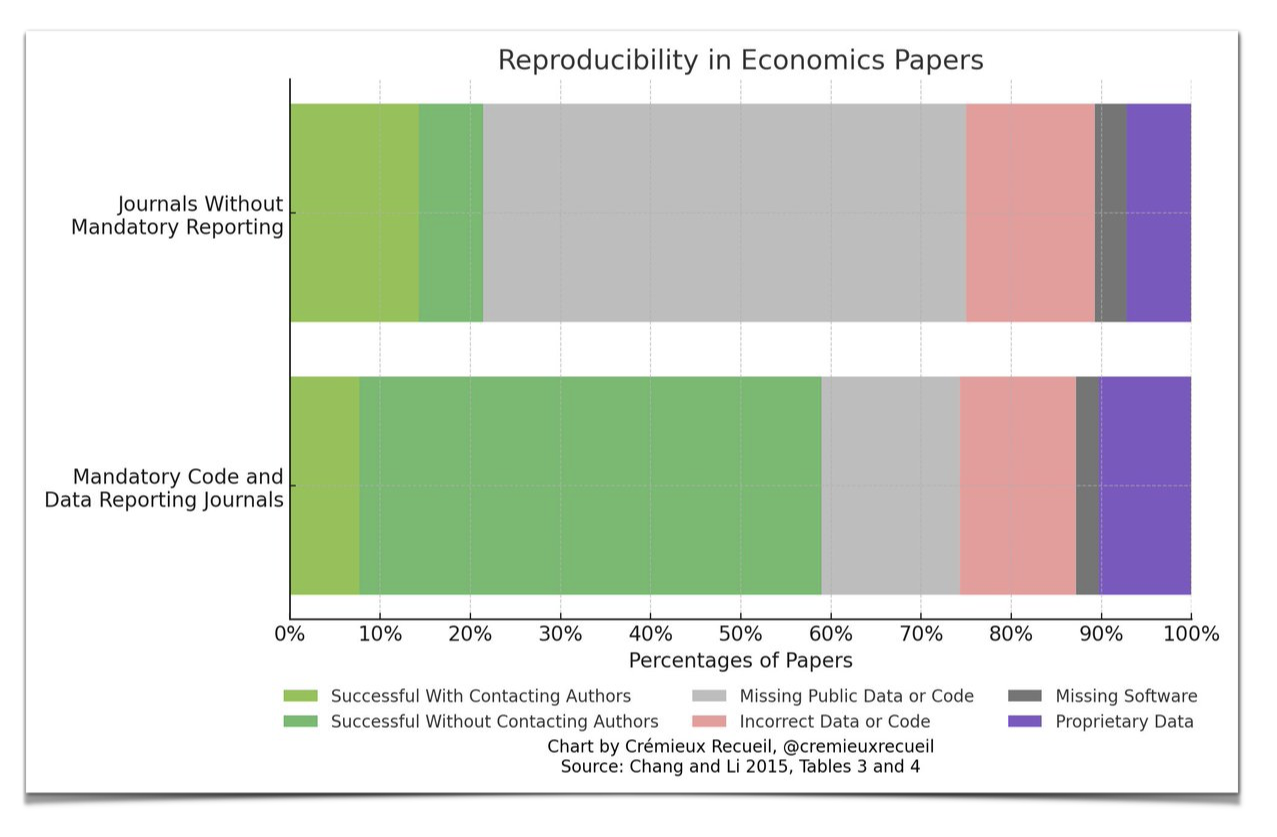
Say it isn’t so! 🤯
A 2024 study on code reproducibility in economics attempted to reproduce 67 economics papers and found that only about 50% were reproducible, even with author assistance and mandatory code-sharing policies at journals!
/{targets}/what-is-it?
It’ll help you go from here…

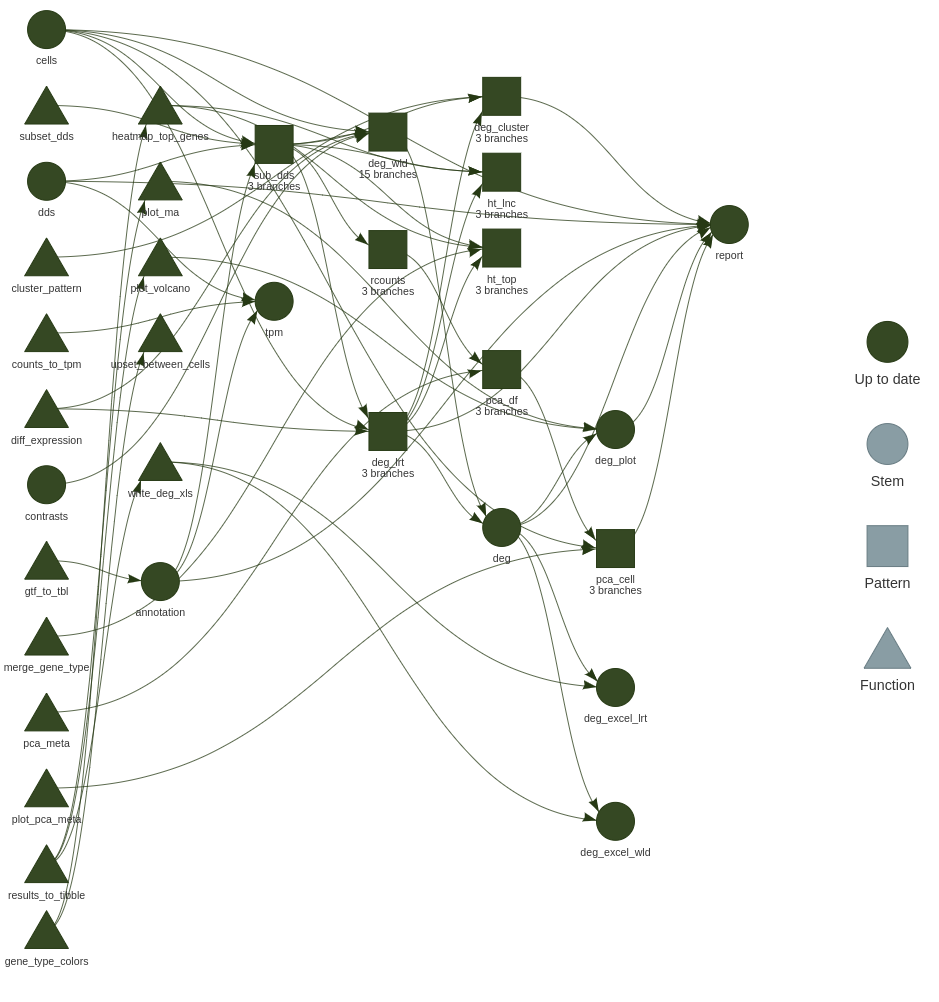
/{targets}/what-is-it?
To here…
/further-reading
We just scratched the surface…
/lets-make-data-science-reproducible!
